Gentzkow and Shapiro¶
Here is a good rule of thumb: If you are trying to solve a problem, and there are multi-billion dollar firms whose entire business model depends on solving the same problem, and there are whole courses at your university devoted to how to solve that problem, you might want to figure out what the experts do and see if you can’t learn something from it.
Gentzkow and Shapiro¶
- This is the spirit of this course.
- We want to learn computation as practised by the experts.
- We don't want to - ever - reinvent the wheel.
Computation Basics¶
- It is important that we understand some basics about computers.
- Even though software (and computers) always get more and more sophisticated, there is still a considerable margin for "human error". This doesn't mean necessarily that there is something wrong, but certain ways of doing things may have severe performance implications.
- Whatever else happens, you write the code, and one way of writing code is different from another.

Julia? Why Julia?¶
- The best software doesn't exist. All depends on:
- The problem at hand.
- You are fine with Stata if you need to run a probit.
- Languages have different comparative advantages with regards to different tasks.
- Preferences of the analyst. Some people just love their software.
- The problem at hand.
- That said, there are some general themes we should keep in mind when choosing a software.
- Stephen Johnson at MIT has a good pitch.
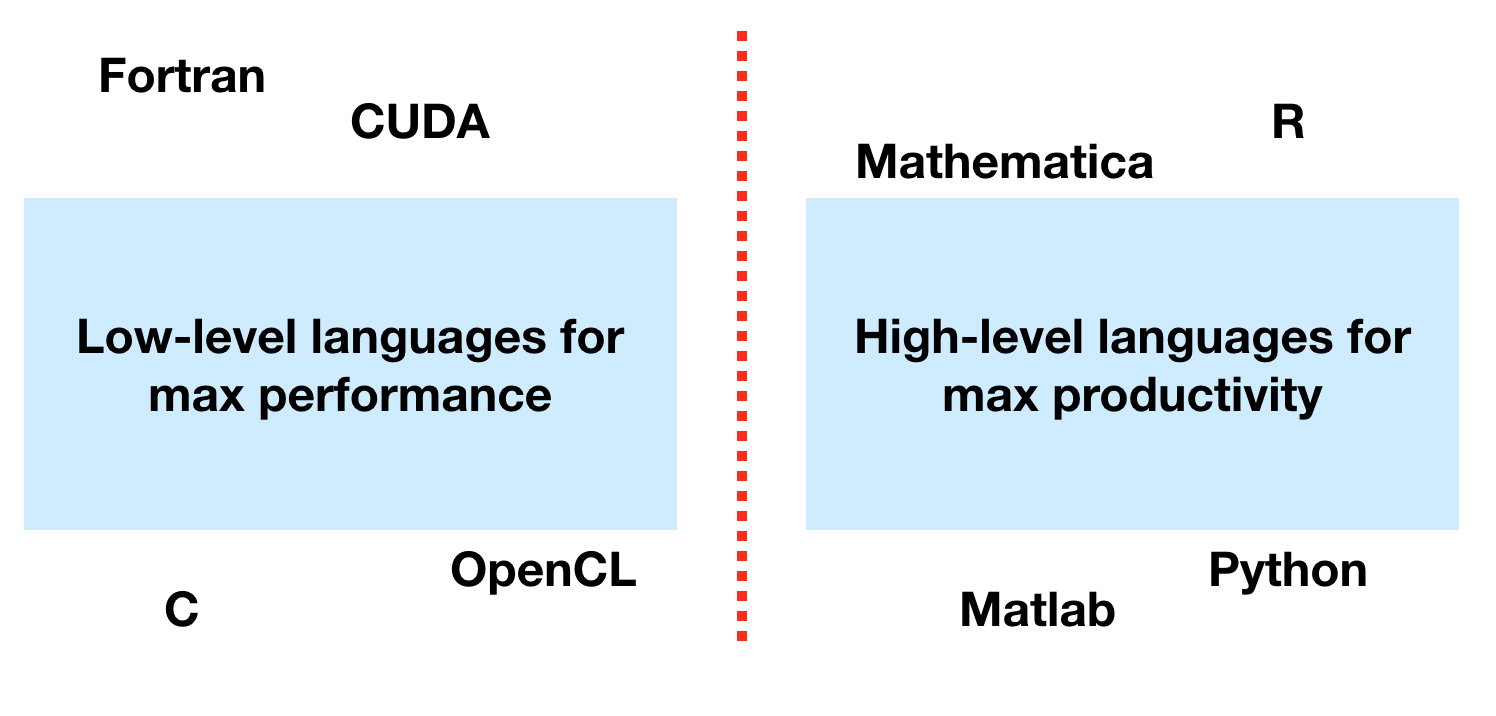
High versus Low Level Languages¶
- High-level languages for technical computing: Matlab, Python, R, ...
- you get going immediately
- very important for exploratory coding or data analysis
- You don't want to worry about type declarations and compilers at the exploratory stage
- High-level languages are slow.
- Traditional Solutions to this: Passing the high-speed threshold.
- Using
RcpporCythonetc is a bit like Stargate. You loose control the moment you pass the barrier toC++for a little bit. (Even though those are great solutions.) If theC++part of your code becomes large, testing this code becomes increasingly difficult. - You end up spending your time coding
C++. But that has it's own drawbacks.
Julia is Fast¶
- Julia is fast.
- But julia is also a high-level dynamic language. How come?
- The JIT compiler.
- The LLVM project.
- Julia is open source (and it's for free)
- It's for free. Did I say that it's for free?
- You will never again worry about licenses. Want to run 1000 instances of julia? Do it.
- The entire standard library of julia is written in julia (and not in
C, e.g., as is the case in R, matlab or python). It's easy to look and understand at how things work.
- Julia is a very modern language, combining the best features of many other languages.
What does Julia want to achieve?¶
- There is a wall built into the scientific software stack
- Julia cofounder Stefan Karpinski talks about the 2 languages problem
- key: the wall creates a social barrier. Developer and User are different people.
The Wall in the scientific software stack¶
Who is using Julia?¶
- Case Studies
- One of the top 10 data sciences problems solved with Celeste.jl
- US Federal Aviation Administration builds their Airborne Collision Avoidance System with julia
- The NY Fed runs their DGSE model in julia
- and more
Economists and Their Software¶
- In A Comparison of Programming Languages in Economics, the authors compare some widely used languages on a close to identical piece of code.
- It can be quite contentious to talk about Software to Economists.
- Religious War.
- Look at the comments on this blog post regarding the paper.
- There are switching costs from one language to another.
- Network effects (Seniors handing down their software to juniors etc)
- Takeaway from that paper:
- There are some very good alternatives to
fortran fortranis not faster thanC++- It seems pointless to invest either money or time in
matlab, given the many good options that are available for free.
- There are some very good alternatives to
The Fundamental Tradeoff¶
Developer Time (Your Time) is Much More Expensive than Computing Time¶
- It may well be that the runtime of a fortran program is one third of the time it takes to run the program in julia, or anything else for that matter.
- However, the time it takes to develop that program is very likely to be (much) longer in fortran.
- Particularly if you want to hold your program to the same quality standards.
Takeaway¶
- Given my personal experience with many of the above languagues, I think
juliais a very good tool for economists with non-trivial computational tasks. - This is why I am using it for demonstrations in this course.
A Second Fundamental Tradeoff¶
- Regardless of the software you use, there is one main problem with computation.
- It concerns speed vs accuracy.
- You may be able to do something very fast, but at very small accuracy (i.e. with a high numerical margin of error)
- On the other hand, you may be able to get a very accurate solution, but it may take you an irrealistic amount of time to get there.
- You have to face that tradeoff and decide for yourself what's best.
A Warning about Optimizing your Code!¶
In Donald Knuth's paper "Structured Programming With GoTo Statements", he wrote:
"Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%."
Julia Workflow¶
- We will use the lastest stable version of julia. today that is
v0.6.2 - For today, stay within this notebook.
- In general, you will want to install julia on your computer
- the most stable workflow involves a text editor and a julia terminal next to it
- You would develop your code in a text file (say "develop.jl"), and then just do
include("develop.jl")in the terminal - I use sublime text as an editor
- Atom is also very good
Some Numerical Concepts and Julia¶
- Machine epsilon: The smallest number that your computer can represent, type
eps(). - Infinity: A number greater than all representable numbers on your computer. Obeys some arithmethmic rules
- Overflow: If you perform an operation where the result is greater than the largest representable number.
- Underflow: You take two (very small) representable numbers, but the result is smaller than
eps(). - In Julia, you are wrapped around the end of your representable space:
x = typemax(Int64) x + 1
- Integers and Floating Point Numbers.
- Single and Double Precision.
- In Julia, all of these are different numeric primitive types (head over to julia manual for a second).
- Julia also supports Arbitrary Precision Arithmetic. Thus, overflow shouldn't become an issue anymore.
- See min and max for different types:
for T in [Int8,Int16,Int32,Int64,Int128,UInt8,UInt16,UInt32,
UInt64,UInt128,Float32,Float64]
println("$(lpad(T,7)): [$(typemin(T)),$(typemax(T))]")
end
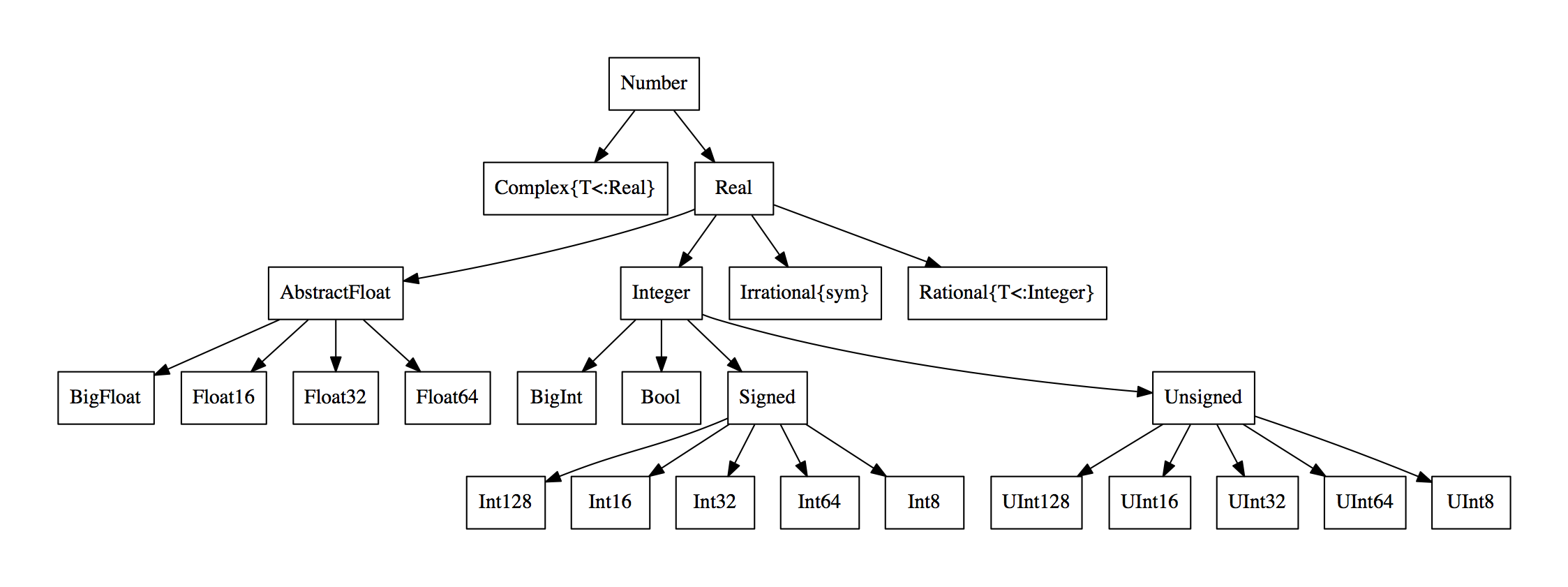
Julia Primer: Types¶
- Types are at the core of what makes julia a great language.
- Everything in julia is represented as a datatype.
- Remember the different numeric types from before? Those are types.
- The manual, as usual, is very informative on this.
- From the wikibook on julia, here is a representation of the numeric type graph:
Julia Primer: Custom Types¶
- The great thing is that you can create you own types.
- Going with the example from the wikibook, we could have types
JaguarandCatas being subtypes ofFeline:
struct Feline
weight::Float64
sound::String
end
struct Cat <: Feline
weight::Float64
sound::String
end
abstract type Feline end
struct Jaguar <: Feline
weight::Float64
sound::String
end
struct Cat <: Feline
weight::Float64
sound::String
end
# is a cat a Feline?
Cat <: Feline
# create a cat and a jaguar
c = Cat(15.2,"miauu")
j = Jaguar(95.1,"ROARRRRRR!!!!!")
# is c an instance of type Cat?
isa(c,Cat)
# methods
function behave(c::Cat)
println(c.sound)
println("my weight is $(c.weight) kg! should go on a diet")
end
function behave(j::Jaguar)
println(j.sound)
println("Step back! I'm a $(j.weight) kg jaguar.")
end
# make a cat behave:
behave(c)
# and a jaguar
behave(j)
Julia Primer: Multiple Dispatch¶
- You have just learned
multiple dispatch. The same function name dispatches to different functions, depending on the input argument type.
Julia Primer: Important performance lesson - Type Stability¶
- If you don't declare types, julia will try to infer them for you.
- DANGER: don't change types along the way.
- julia optimizes your code for a specific type configuration.
- it's not the same CPU operation to add two
Ints and twoFloats. The difference matters.
- Example
function t1(n)
s = 0 # typeof(s) = Int
for i in 1:n
s += s/i
end
end
function t2(n)
s = 0.0 # typeof(s) = Float64
for i in 1:n
s += s/i
end
end
@time t1(10000000)
@time t2(10000000)
Julia Modules¶
- A module is a new workspace - a new global scope
- A module defines a separate namespace
- There is an illustrative example available at the julia manual, let's look at it.
An example Module¶
module MyModule
# which other modules to use: imports
using Lib
using BigLib: thing1, thing2
import Base.show
importall OtherLib
# what to export from this module
export MyType, foo
# type defs
struct MyType
x
end
# methods
bar(x) = 2x
foo(a::MyType) = bar(a.x) + 1
show(io::IO, a::MyType) = print(io, "MyType $(a.x)")
end
Modules and files¶
- you can easily have more files inside a module to organize your code.
- For example, you could
includeother files like this
module Foo
include("file1.jl")
include("file2.jl")
end
Working with Modules¶
- Look at the example at the manual!
- Location of Modules: Julia stores packages in a hidden folder
~/.julia/v0.6(system-dependent) - You can develop your own modules in a different location if you want.
- Julia reads the file
~/.juliarc.jlon each startup. Modify theLOAD_PATHvariable:
# add this to ~/.juliarc.jl
push!(LOAD_PATH, "/Path/To/My/Module/")
Unit Testing and Code Quality¶

What is Unit Testing? Why should you test you code?¶
- Bugs are very hard to find just by looking at your code.
- Bugs hide.
- From this very instructive MIT software construction class:
Even with the best validation, it’s very hard to achieve perfect quality in software. Here are some typical residual defect rates (bugs left over after the software has shipped) per kloc (one thousand lines of source code):
- 1 - 10 defects/kloc: Typical industry software.
- 0.1 - 1 defects/kloc: High-quality validation. The Java libraries might achieve this level of correctness.
- 0.01 - 0.1 defects/kloc: The very best, safety-critical validation. NASA and companies like Praxis can achieve this level. This can be discouraging for large systems. For example, if you have shipped a million lines of typical industry source code (1 defect/kloc), it means you missed 1000 bugs!
Unit Testing in Science¶
- One widely-used way to prevent your code from having too many errors, is to continuously test it.
- This issue is widely neglected in Economics as well as other sciences.
- If the resulting graph looks right, the code should be alright, shouldn't it?
- Well, should it?
- It is regrettable that so little effort is put into verifying the proper functioning of scientific code.
- Referees in general don't have access to the computing code for paper that is submitted to a journal for publication.
- How should they be able to tell whether what they see in black on white on paper is the result of the actual computation that was proposed, rather than the result of chance (a.k.a. a bug)?
- Increasingly papers do post the source code after publication.
- The scientific method is based on the principle of reproduciblity of results.
- Notice that having something reproducible is only a first step, since you can reproduce with your buggy code the same nice graph.
- But from where we are right now, it's an important first step.
- This is an issue that is detrimental to credibility of Economics, and Science, as a whole.
- Extensively testing your code will guard you against this.
Best Practice¶
- You want to be in maximum control over your code at all times:
- You want to be as sure as possible that a certain piece of code is doing, what it actually meant to do.
- This sounds trivial (and it is), yet very few people engage in unit testing.
- Things are slowly changing. See http://www.runmycode.org for example.
- You are the generation that is going to change this. Do it.
- Let's look at some real world Examples.
Ariane 5 blows up because of a bug¶
It took the European Space Agency 10 years and $$7 billion to produce Ariane 5, a giant rocket capable of hurling a pair of three-ton satellites into orbit with each launch and intended to give Europe overwhelming supremacy in the commercial space business. All it took to explode that rocket less than a minute into its maiden voyage last June, scattering fiery rubble across the mangrove swamps of French Guiana, was a small computer program trying to stuff a 64-bit number into a 16-bit space. This shutdown occurred 36.7 seconds after launch, when the guidance system's own computer tried to convert one piece of data -- the sideways velocity of the rocket -- from a 64-bit format to a 16-bit format. The number was too big, and an overflow error resulted. When the guidance system shut down, it passed control to an identical, redundant unit, which was there to provide backup in case of just such a failure. But the second unit had failed in the identical manner a few milliseconds before. And why not? It was running the same software.
NASA Mars Orbiter crashes because of a bug¶
For nine months, the Mars Climate Orbiter was speeding through space and speaking to NASA in metric. But the engineers on the ground were replying in non-metric English. It was a mathematical mismatch that was not caught until after the $$125-million spacecraft, a key part of NASA's Mars exploration program, was sent crashing too low and too fast into the Martian atmosphere. The craft has not been heard from since. Noel Henners of Lockheed Martin Astronautics, the prime contractor for the Mars craft, said at a news conference it was up to his company's engineers to assure the metric systems used in one computer program were compatible with the English system used in another program. The simple conversion check was not done, he said.
LA Airport Air Traffic Control shuts down because of a bug¶
(IEEE Spectrum) -- It was an air traffic controller's worst nightmare. Without warning, on Tuesday, 14 September, at about 5 p.m. Pacific daylight time, air traffic controllers lost voice contact with 400 airplanes they were tracking over the southwestern United States. Planes started to head toward one another, something that occurs routinely under careful control of the air traffic controllers, who keep airplanes safely apart. But now the controllers had no way to redirect the planes' courses. The controllers lost contact with the planes when the main voice communications system (VCS) shut down unexpectedly. To make matters worse, a backup system that was supposed to take over in such an event crashed within a minute after it was turned on. The outage disrupted about 800 flights across the country. Inside the control system unit (VCSU) is a countdown timer that ticks off time in milliseconds. The VCSU uses the timer as a pulse to send out periodic queries to the VSCS. It starts out at the highest possible number that the system's server and its software can handle — 232. It's a number just over 4 billion milliseconds. When the counter reaches zero, the system runs out of ticks and can no longer time itself. So it shuts down. Counting down from 232 to zero in milliseconds takes just under 50 days. The FAA procedure of having a technician reboot the VSCS every 30 days resets the timer to 232 almost three weeks before it runs out of digits.
Automated Testing on Travis¶
- https://travis-ci.org is a continuous integration service.
- It runs your test on their machines and notifies you of the result.
- Every time you push a commit to github.
- If the repository is public on github, the service is for free.
- Many julia packages are testing on Travis.
- You should look out for this green badge:

- You can run the tests for a package with
Pkg.test("Package_name") - You can run the tests for julia itself with
Base.runtests()
# let's do some simple testing
using Base.Test
@test 1==1
@test pi ≈ 3.14159 atol=1e-4
@test 2>3
Debugging Julia¶
There are at least 2 ways to chase down a bug.
- Use logging facilities.
- poor man's logger: write
printlnstatements at various points in your code. - better: use Base.logging
- this will really become useful in v1.0, when you can choose the logging level in a better way.
- poor man's logger: write
- Use the debugger:
- The Julia debugger used to be Gallium.jl
- There is a lot of work on that repo. in the meantime:
- https://github.com/Keno/ASTInterpreter2.jl works very well.
- Debugging works well in Juno.
- We will try this out next time, when you start to work with actual code.
- The Julia debugger used to be Gallium.jl
Julia and Data¶
- There is a github org for julia and data
- Some prominent members of that org are
What's special about Data?¶
- There are several issues when working with data:
- A typical dataset might be deliverd to you in tabular form. A comma separated file, for example: a spreadsheet.
- R, julia and python share the concept of a
DataFrame. A tabular dataset with column names. - that means in particular that each column could have a different datatype.
- For a language that optimizes on efficiently computing with different datatypes, that is a challenge.
- Importantly: data can be missing, i.e. for several reasons there is a record that was not, well, recorded.
- Julia has made a lot of progress here. We now have the
Missingdata type, provided inMissings.jl
using DataFrames # DataFrames re-exports Missings.jl
m = missings(Float64,3) # you choose a datatype, and the dims for an array
m[1:2] = ones(2)
sum(m) # => missing. because Float64 + missing = missing
prod(m) # => missing. because Float64 * missing = missing
sum(skipmissing(m)) # => 2
# you can replace missing values
println(typeof(Missings.replace(m,3)))
collect(Missings.replace(m,3))
DataFrames¶
- A dataframe is a tabular dataset: a spreadsheet
- columns can be of different data type. very convenient, very hard to optimize.
df = DataFrame(nums = rand(3),words=["little","brown","dog"])
# there is alot of functionality. please consult the manual.
df[:nums]
df[:words][1] # "little"
df[:nums][2:3] = [1,1]
df
using RDatasets # popular Datasets from R
iris = dataset("datasets", "iris")
head(iris) # get the first 6 rows
println(iris[:SepalLength][1:6]) # get a column
show(iris[2,:]) # get a row
describe(iris); # get a description
d = DataFrame(A = rand(10),B=rand([1,2],10),C=["word $i" for i in 1:10])
by(d,:B,x->mean(x[:A]))
# subsetting a dataframe can become cumbersome
d = DataFrame(A = rand(10),B=rand([1,2],10),C=["word $i" for i in 1:10])
d[(d[:A].>0.1) .& (d[:B].==2),:] # approach 1
using DataFramesMeta
@where(d,(:A .>0.1) .& (:B.==2)) # approach 2
enter
DataFramesMeta.jl¶
- This makes this much easier.
- It makes heavy use of macros.
- The same thing from before is now
using DataFramesMeta
@where(d,(:A .>0.1) & (:B.==2))
- We can access column names as symbols inside an expression.
# the previous operation would become
@by(d,:B,m=mean(:A))
Chaining operations¶
- Very often we have to do a chain of operations on a set of data.
- Readibility is a big concern here.
- Here we can use the
@linqmacro together with a pipe operator. - This is inspired by
LINK(language integrated query) from microsoft .NET
df = DataFrame(a = 1:20,b = rand([2,5,10],20), x = rand(20))
x_thread = @linq df |>
transform(y = 10 * :x) |>
where(:a .> 2) |>
by(:b, meanX = mean(:x), meanY = mean(:y)) |>
orderby(:meanX) |>
select(meanx=:meanX,meany= :meanY, var = :b)
# or
# using Lazy
# x_thread = @> begin
# df
# @transform(y = 10 * :x)
# @where(:a .> 2)
# @by(:b, meanX = mean(:x), meanY = mean(:y))
# @orderby(:meanX)
# @select(:meanX, :meanY, var = :b)
# end
an alternative
Query.jl¶
- Much in the same spirit. But can query almost any data source, not only dataframes.
- Data Sources: DataFrames, Dicts, Arrays, TypedTables, DataStreams,...
- Data Sinks: DataFrames, Dicts, Csv
- It is not as convenient to summarise data, however.
- It is one of the best documented packages I know.
- In general, a query looks like this:
q = @from <range variable> in <source> begin <query statements> end
- Here is an example:
using Query
df = DataFrame(name=["John", "Sally", "Kirk"], age=[23., 42., 59.], children=[3,5,2])
x = @from i in df begin
@where i.age>50
@select {i.name, i.children}
@collect DataFrame
end
println(df)
println(x)
you can do several things in a query:
- sort
- filter
- project
- flatten
- join
- split-apply-combine (dplyr)
df = DataFrame(name=repeat(["John", "Sally", "Kirk"],inner=[1],outer=[2]),
age=vcat([10., 20., 30.],[10., 20., 30.].+3),
children=repeat([3,2,2],inner=[1],outer=[2]),state=[:a,:a,:a,:b,:b,:b])
x = @from i in df begin
@group i by i.state into g
@select {group=g.key,mage=mean(g..age), oldest=maximum(g..age), youngest=minimum(g..age)}
@collect DataFrame
end
println(x)